Yoshua Bengio:注意力是“有意识”AI的核心要素

注意力机制或许是未来机器学习的核心要素。
在本周举办的ICLR 2020 上,图灵奖获得者Yoshua Bengio 在其特邀报告中着重强调了这一点。
目前注意力机制已是深度学习里的大杀器,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。
借鉴于人类的注意力机制,关注注意焦点,注意力机制是作为一种通用的思想出现的。
Bengio在其报告《与意识相关的深度学习先验》中提到,丹尼尔·卡尼曼的书《思考,快与慢》中指出人的认知系统有两类,一类是无意识(快系统)的,关键词是直觉、非语言、习惯;第二类是有意识的(慢系统),关键词是语言性、算法性,推理和计划。
Bengio指出,第二类认知系统允许对语义概念进行操纵、重组,这对于当前的人工智能和机器学习算法来说是一个非常渴望的特性。
但目前的机器学习方法还远没有从无意识发展到全意识,但是Bengio相信从“无”到“有”的转变完全可能,而注意力则是转变过程的核心要素之一。
在报告中,Bengio提到,注意力机制每次都关注其中某几个概念并进行计算,因为意识先验及其相关的假设中,许多高层次的依赖关系可以被一个稀疏因子图近似地捕捉到。
最后,报告介绍了元学习,这种先验意识和代理视角下的表征学习,会更加有助于以新颖的方式,支持强大的合成泛化形式。
AI科技评论对演讲内容做了有删改的翻译整理,供大家参考:
Bengio:

此次报告的主题是深度学习的未来发展方向,特别是深度学习与意识的关系。其实神经科学对意识内容的研究在近几十年里已经有了很大的进展。

所以现在是机器学习考虑这些将意识加入模型的时候了。另一方面,这对意识的研究也有好处,能够在测试意识的特定假设功能以及正式化方面提供帮助,也能够让我们从意识中获得一些魔力,并理解意识的进化优势、计算和统计优势。
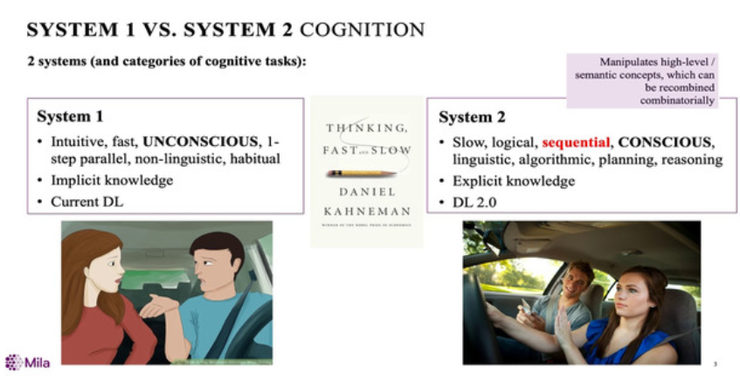
对于意识,丹尼尔·卡尼曼在《思考,快与慢》这本书中,对许多常见的现象如直觉、错觉、偏见等给出了科学解释,并介绍了“系统1,系统2”,描述了大脑的两种思维模式。
对于[系统1],可以想象这样的场景:在一条你已经非常清楚路况的公路上开汽车,这时候,你并没有把所有的注意力都放在驾驶上,如果有人和你进行谈话,你也可以轻松回应。
相反,[系统2]的场景描述就是:如果你在一个新的地方开车,这时候别人和你对话,你会非常烦,因为你要把精力都放在驾驶上。
所以「系统1」的任务涉及到直觉知识,它能够很快执行,在你大脑中是不知不觉一步一步发生的。「系统1」通常涉及隐性知识,很难用语言解释,但是人工神经网络却擅长存储隐性知识,这也是现在深度学习表现非常好的原因。
而「系统2」的任务更多的需要以一种有意识的方式,按照顺序并能够用语言来描述,这也是所谓的显性知识,涉及到了推理和规划的算法。
所以「系统2」在做任务执行的时候可能非常慢,但里面的涉及的关键确是我们想给深度学习进一步扩展的功能。
简单而言,「系统2」任务的一个有趣的特性是允许操纵高级语义概念,这些概念可以在新的情况下使用,并与分布外的泛化相联系,而未来的深度学习需要的正是种“操纵”功能。

认知角度来说,我们大脑中关于世界的知识认知可以分为两类:隐性知识和显性知识。能够语言化的其实是一种特殊的知识,我们应该试着去描述和刻画,这样才能把它放在模型的训练框架中。而且,这些知识是围绕着我们可以用语言命名的概念来组织的。因此,这些研究和建立更好的自然语言理解之间有很强的联系。

将意识加工到深度学习需要先验知识。那么什么样的先验知识能够帮助扩展深度学习,并使其融入高级概念和「系统2」任务存在的那种结构?
第一个前提是有些高级别之间的联合分布的结构,也称为语义变量。联合分布可以用图形模型来描述,特别是因子图,因为它是稀疏的,每个知识涉及的很少。此外,这些变量往往与因果关系有关。
还有一个假设,是关于高层次变量的,即思想和单词和句子之间有一种简单的关系,以便可以表达有意识的想法。
例如,在编程或逻辑思维中,有些知识是可以重用的,可以将它们视为跨多个实例应用的规则,当然也可以视为类似于函数的参数。
还有一个重要的问题,是考虑变量中的数据类型如何随时间变化,概率分布如何随时间变化。搞清楚这些非常重要,因为这些变量可能是因果关系的闪光符。这里面涉及的假设是:当分布发生变化时,其余的联合分布大多不会随着关系的变化而变化。
还需要注意的一点是,我们的观察、感官数据、低级动作和高级变量,当有干预时,唯一会改变的是高水平变量的某些性质,而不是它们与低水平知觉的关系。
最后一个假设是关于推理和计划,以及什么对这些变量进行分配(Credit Assignment),这里的假设是:在此进行的信用分配涉及较短的成本变化。
符合以上假设的先验知识能够帮助扩展深度学习。

然后看一下「系统 2 」的任务涉及的有趣性质,也就是所谓的系统概括能力,专业的语言学已经对此做了非常多的研究,这些研究发现人类可以动态的重新组合现有的概念来形成一个新的概念。
这些概念可以是口头的,也可以是视觉的,如上图所示,不同类型的车辆组合在一起形成了一个新的概念,这种概念的重组能够解释我们从未见到过的观测结果,即使是在训练分布概率为零的条件下也可以。
对于此种现象,到目前为止,我们在多篇论文中实验观察到的是,当分布发生这样的变化时,当前的深度学习系统表现不是很好,而且他们往往会发生过拟合。

显然,AI并不能像人类做的那样好,经典的人工智能程序想要两全其美,就要避免经典的基于人工智能规则的符号操作的陷阱。
这就需要把通过深度学习取得的一些成果保留,如高效-大规模学习,语义基础、以及「系统1」中的知识表达、以及机器学习正确处理不确定性的能力。
但是,我们想要的是一些与「系统2」相关优势,即将知识分解之后,我们可以操纵变量、实例以及引用。
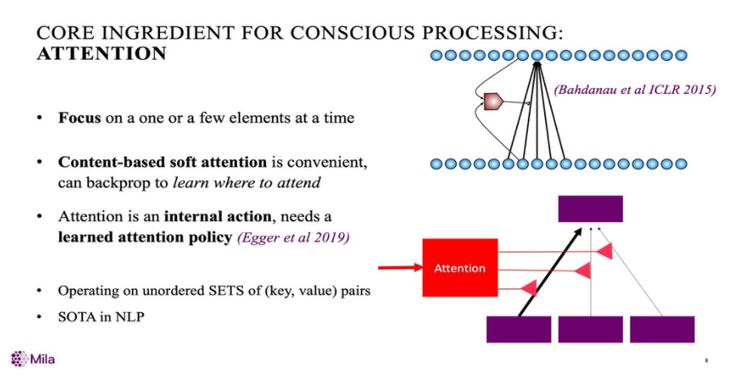
接下来看一下注意力机制,在过去的几年里,在深度学习方面,soft attention此类的工具已经取得了进展,这可能是我们过渡到“未来深度学习”的关键,即获得从处理向量到能够“操纵”的功能。
从机器翻译开始,soft attention已经对自然语言处理产生了巨大的影响,一些有趣的神经科学表明,这种注意力在就像是内部的一种肌肉运动。
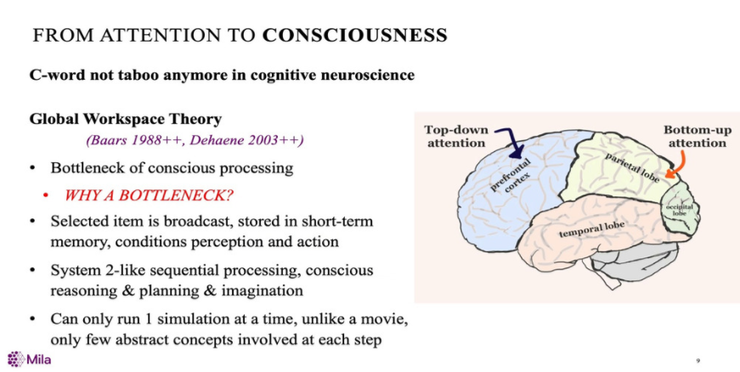
上面是神经科学中关于意识的几个理论的核心,尤其是全局工作空间理论,大多数是由Baars提出,涉及了意识过程的瓶颈问题。
当前通常认为信息是用注意力来选择的,即从多种可能的方式和输入的部分中选择信息,然后将选择的信息广播到大脑的其他部分,并存储在短期记忆中,以适应短期内的感知和行动。
这里有一个有趣的事情要注意,如果我们认为大脑的大脑皮层是一个大的模拟引擎,那么就要假设一次只能运行一次“全”模拟,区别于每一步只涉及几个抽象的概念的“电影模式”。

从人们的口头报告中,我们就可以判断某些事件是有意识的还是无意识的。其实,不光是口头报告,理解也非常重要,因为它能将高级别的示与较低级别感知联系在一起。但也有很多关于这个世界的知识不能用我刚才谈到的那些强有力的假设来代表。

2017年的时候,我在论文中曾经提到过意识先验,如果用因果图来表示的话,可以把每个因子像句子一样看成是涉及几个变量的联合分布。
高级语言会有一个惊人的特性,那就是我可以在一句话中做出隐蔽性的预测。例如,“如果我扔一个球,这个球会掉在地上”
另外还可以做一个只涉及少数几个概念的强有力的预测,不同于通常的边际独立假设,我们假设高级变量是独立的。
这些都与我刚才谈到的注意力的概念有关,因为当你想要对这样一个稀疏的图表进行推理时,一个合理的方法是一次只关注一个或几个因素。
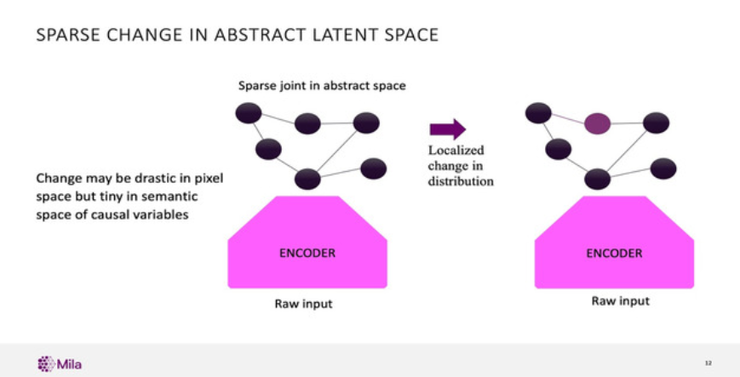
关于事物在分布上可能如何变化的假设也非常重要,因为它能够提供了一些“意识处理”的强大力量。
想象这样一个画面:有一个原始数据,它有一个非常复杂的联合分布,我们将用两个层次来表示它。然后将四分之一的原始数据映射到抽象空间,根据这个假设,当分布发生变化时会发生什么?
其实,在抽象空间中,更改是局部化的,可能只需要修改一个变量、一个条件或一个因素。因此,学习如何适应修改后的分布变得容易得多,如果以正确的方式表示信息,就可以快速传输。

这些变化是怎么造成的呢?很可能是因为一个Agent在全局中做了一些事情。由于物理行为在空间和时间上都是局部化的,Agent只能以局部化的方式做事情。
例如,如果我戴上墨镜,在较高的水平上,只能看到一点点变化,但在较低的水平,变化非常大,因为所有的像素都有不同的联合分布。
分布变了之后会发生什么呢?一般机器学习模型训练都假设使用的数据是服从独立同分布,但这显然不符合实际情况。于是,我们使用一个元学习目标来学习如何将获得的知识模块化,并找到其中的因果关系。
具体而言,我们在简单的设置中尝试了这个想法,首先,用两个变量a和b,通过改变分布来学习,对其中一个变量的干预,在这种情况下,我们发现了学习的速度。
这个发现是一个很好的线索,意味着你是否有正确的假设,是否有正确的高级变量集。关于A和B谁是谁的原因,我们最近在理论方面扩展了这项工作,证明了什么时候可以收敛到正确的因果假说。译者注:论文是《一个元转移的目标学习解开因果机制》
地址:https://openreview.net/forum?id=ryxWIgBFPS
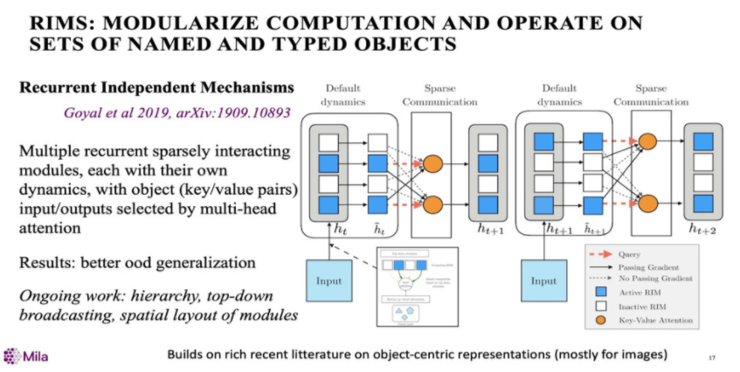
最后,提一下我想提的工作,一篇叫做《Recurrent Independent Mechanisms》的论文里面重新定义了一个新的recurrent neural net架构,在这个架构中,把recurrent net 分解成更小的模块,在每个模块里面,它是完全连接在一起的,并不是一个同质的网络。模块之间,有一个注意力机制,当然,你也可以认为这是意识的集中地。
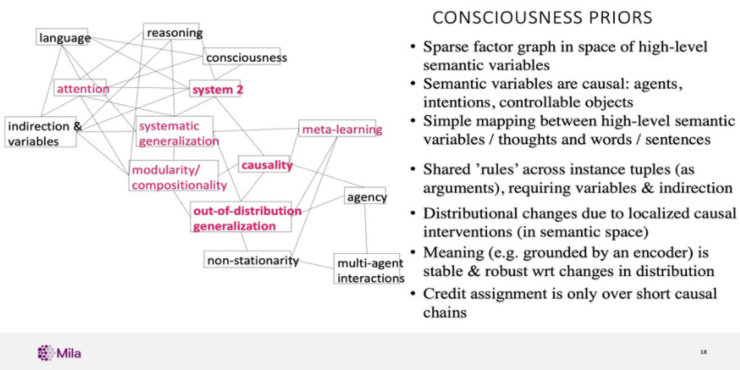
总结一下,在前面的演讲中,我试图为深度学习勾勒出一个研究方向,为深度学习捕捉「系统1」的知识。我发现这里面有很多有趣的研究方面,例如系统之外的东西、事物的分布、知识的呈现方式......
解决这些问题,知识先验是一个非常好的想法,可以让知识分解重组然后对应依赖性的知识,并且能够涉及非常少的变量。显然,这非常有趣,因为它允许一个Agent能够快速的适应分布的变化。
已获取点赞 +0
评论 点击评论